
Hadoop a Elasticsearch, Big Data
Co jsou Big Data
Big Data je populární výraz jak popsat exponenciální růst objemu dat, jak strukturovaných, tak i nestrukturovaných. A Big Data můžou být pro vás velice důležitá, obzvláště pro váš business. Proč? Tak například proto, že s mnohem více daty jste schopni dělat mnohem lepší business analýzy, můžete z nich těžit velké množství užitečných informací a nebo je můzete jen prostě skladovat pro případné další využití.
Big Data typicky znamenají
- Tradiční enterprise data - mohou to být různá data o zákaznících, ERP data, obchodní transakce.
- Strojově generovaná data a data z různých senzorů - tady se jedná o ruzné logy, měření, výrobní senzory, GPS data.
- Sociální data - zde to můžou být různé mikro blogovací systémy jako Twitter, sociální platformy jako Facebook, webová analytika.
I když taková nejvýznamnější charakteristika, která definuje Big Data je objem dat, tak to není zdaleka jediná. Mezi další pak patří i rychlost. Máte například úlohy, kdy potřebujete řešit okamžité zpracování velkého objemu průběžně vznikajících dat. Dále pak to je variabilita, kdy můžete zpracovávat kromě strukturovaných dat i nestrukturovaná data či multimediální data. Hodnota je další význačnou charakteristikou, kdy významná informační hodnota je často schovaná v nějaké velké skupině zdánlivě nesourodých informací a je pak výzva tuto hodnotu najít a zužitkovat k vašemu prospěchu.
Hadoop ekosystém
Hadoop je komplexní ekosystém, který se používá k ukládání obrovského množství informací na běžný hardware (ano, není třeba žádný enterprise úložný systém). Nad těmito daty se pak provádí různé analýzy, reportování a další.
Hadoop se skládá ze dvou hlavních částí:
- HDFS - což je distribuovaný souborový systém.
- MapReduce - což je modul pro distribuovaní zpracování.
Na následujícím obrázku je pak vidět, jak celý systém vypadá.
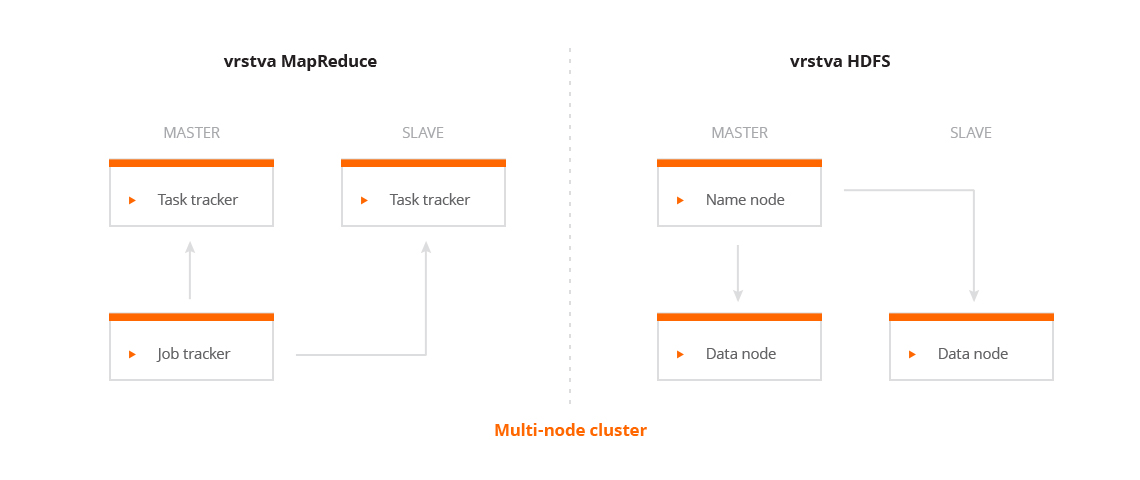
Kromě těchto dvou základních částí je v Hadoop k dispozici Hadoop YARN, který řídí zdroje v clusteru. Existuje celá řada systémů, které běží na Hadoopu. Mezi ně patří například Mahout, HBase, Hive, Elasticsearch, Pig atp. Konkrétní použití těchto navzájem se doplňujících systémů pak závisí čistě na daném případu u zákazníka.
A proč je Hadoop důležitý? Asi největší důvod je, že dokáže obsluhovat obrovské množství dat velice rychle. Mezi další důvody patří zejména:
- Nízké náklady - je to open source framework a využívá k ukládání dat běžný hardware, neplatíte žádné licence.
- Výpočetní výkon - jeho distribuovaný výpočetní model umí rychle zpracovat i velké množství dat (čím více nodů, tím více výkonu).
- Škálovatelnost - začnete s málem a postupně můžete jednoduše přidávat další nody.
- Flexibilita - narozdíl od relačních databází nemusíte data předzpracovávat předtím, než je uložíte. Prostě toho uložíte kolik chcete a až později se rozhodnete, jak data zpracovávat.
- Ochrana dat - data i jejich zpracování je chráněno před selháním hardware. Pokud selže jeden node, práce na něm prováděná je automaticky převedena na další nódy. Tím se zajistí, že distribuovaný výpočet neselže. Všechny data jsou automaticky replikována na jiné nódy dle replikačního faktoru.
Elasticsearch
U mnoha klientů vzniká současně s Big Data požadavek na uložení obrovských množství dat, které obsahují určitou strukturu a je s nimi potřeba v reálném čase pracovat, například provádět fulltext vyhledávání, fuzzy vyhledávání nebo se podle určitých dat online rozhodovat. Zde je výhodné na Hadoop napojit Elasticsearch, který je přesně pro tyto účely vyvinut. Data se pak nejprve posílají do Elasticsearch a po zpracování (nebo současně, záleží na konkrétních požadavcích) se odešlou do Hadoop clusteru. Elasticsearch je svým provozem a instalací velmi podobný Hadoopu, proto pro něj platí také výše zmíněné vlastnosti:
- Nízké náklady - je to open source framework a využívá k ukládání dat běžný hardware, neplatíte žádné licence.
- Výpočetní výkon - jeho distribuovaný výpočetní model umí rychle zpracovat i velké množství dat (čím více nodů, tím více výkonu).
- Škálovatelnost - začnete s málem a postupně můžete jednoduše přidávat další nody.
- Flexibilita - narozdíl od relačních databází nemusíte data předzpracovávat předtím, než je uložíte. Prostě toho uložíte kolik chcete a až později se rozhodnete, jak data zpracovávat.
- Ochrana dat - data i jejich zpracování je chráněno před selháním hardware. Pokud selže jeden node, práce na něm prováděná je automaticky převedena na další nódy. Tím se zajistí, že distribuovaný výpočet neselže. Všechny data jsou automaticky replikována na jiné nódy dle replikačního faktoru.
Analýza dat
Řekněme, že již ukládáme obrovské množství vašich dat do Hadoop (nebo Hadoop + Elasticsearch) clusteru. Co pak s nimi můžeme dělat? Odpověď je jednoduchá, můžeme nad nimi vytvářet složité analýzy a reporty, sledovat "na živo" realná data v určitém časovém intervalu, online dělat automatická rozhodnutí na základě dat v clusteru (např. sledovat logy všech vašich aplikací a na jejich základě provádět automaticky činnosti, které potřebujete) a mnoho dalšího.
Analytika vám umožňuje vidět lépe váš potenciál v obchodě, můžete lépe cílit svoji reklamu, utvářet efektivní obchodní strategie, analyzovat zpětnou vazbu vašich klientů na vaše produkty či služby, kategorizovat data a mnoho dalšího. Toto je vám schopno zvednou kredit i zisk vaší společnosti při zachování velmi nízkých vstupních investic. Navíc okamžitě snížíte (někdy úplně odstraníte) náklady na činnostech, které jste dříve neměli automatizovány. Pomocí Big Data, práce Mule ESB a dalšího software budete mít procesy, které si přejete, plně automatizovány!
Naše řešení
Nabízíme vám kvalitní služby profesionálů v oblasti Big Data a analýzy dat, instalaci a údržbu celé platformy (případně proškolení vašeho personálu). Samozřejmost je vývoj řešení přímo na míru, v této oblasti to ani jinak nejde, protože každý zákazník má jiné business požadavky a potřebuje sledovat a zpracovávat jiná data (avšak mnoho komponent lze použít obecně a vývoj tak není nikdy "na zelené louce"). Někteří naši klienti vyhodnocují online data z clusteru Elasticsearch (milióny záznamů) a odesílají sms zprávy, jiní do clusterů ukládají všechny informace z internetu (včetně některých sociálních sítí) o svých zákaznících (aktivně sbírá Mule ESB), někteří naši klienti "jen" sbírají logy aplikací do Elasticserach clusteru a tyto pak sledují... Vidíte, že portfólio použití je různorodé. S námi vás nic neomezuje, pokud máte jakýkoliv nápad, potřebu nebo představu, vždy vám zaručíme kvalitní a rozšiřitelné řešení.
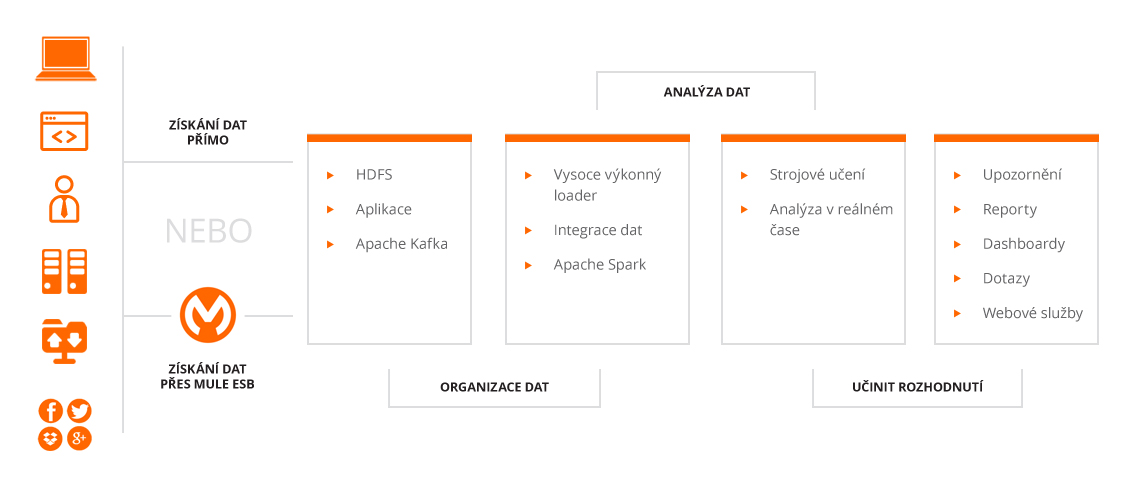
Naše Big Data je založeno na Hadoop clusteru (popř. Elasticsearch pokud je potřeba) a velice výkonných distribuovaných výpočetních systémech, které vám umožní rychlý přístup k vašim datům. Současně se s Big Data řešením často vyskytuje požadavek na integraci existujících systémů pomocí Mule ESB a integraci uživatelů (i zákaznických účtů) přes Keycloak SSO tak, aby mohly z těchto systémů proudit data přímo do clusteru Hadoop a nebo Elasticsearch pro další zpracování.
Stručně některé naše projekty
- Nasazení Big Data - mnoho produkčních nasazení technologie Hadoop, Elastic a OrientDB (některé volně svázány s datovými gridy, jako např. Infinispan).
- Nástroj reportingu BI - moderní nástroj reportingu BI napojený na obrovská množství dat uložených v Hadoop clusteru.
- Big Data loader - nástroj Big Data loader pro platformu Hadoop.
- Nástroj pro analýzy business - nástroj pro sběr užitečných informací o business s využitím různých statistických metod.